I’ve been using GitHub Copilot for Unity development and it is incredible. It has saved me from tons of bugs, speeded up my work by 2x, and even taught me a lot of C# (which Unity uses and I haven’t used before).
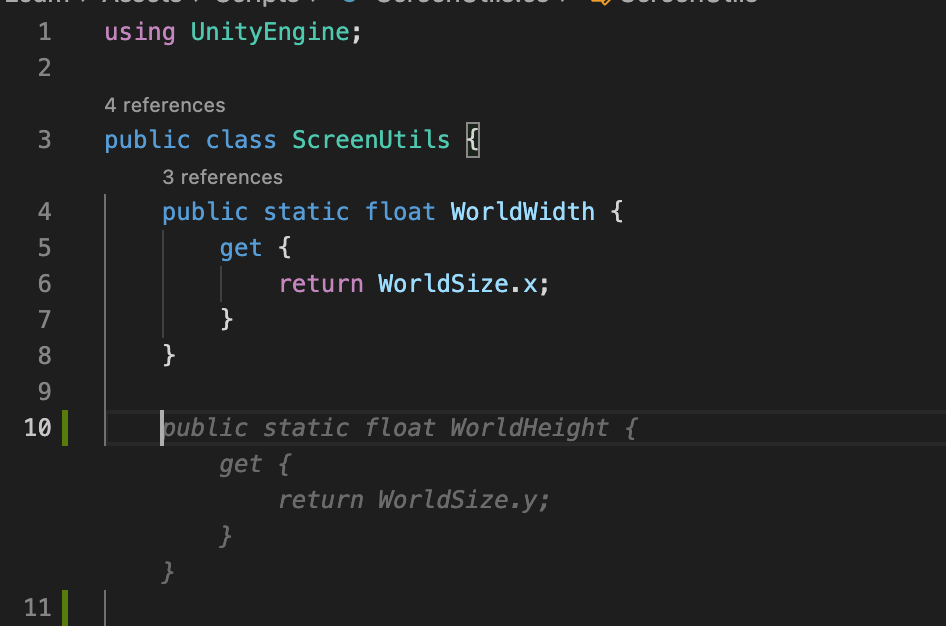
How does it work? You install it as a VS Code extension and then, as you type, it (very magically) suggests what should come next. For example, I have a very simple utility class with a static field, WorldWidth, to get the size of the screen in world coordinates. Suppose I wanted to add a WorldHeight field. I press enter, and I literally don’t even have to start typing:
It knows that this is the other function I’d likely want.
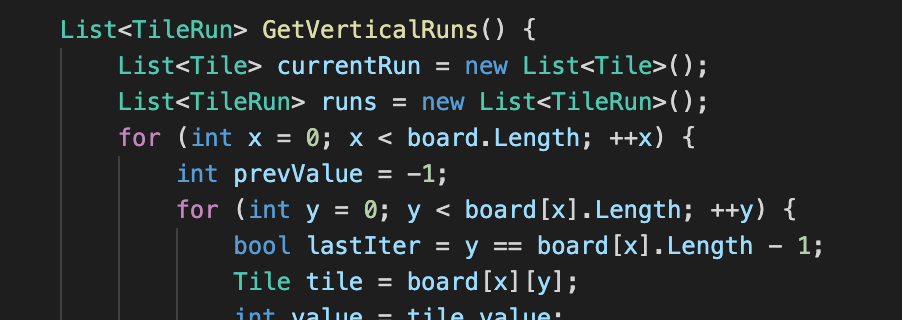
Okay, but that’s very simply. How about something more complex? This is a long function, so excerpting part of it, but it’s a nested for loop that looks at each column on the game board.
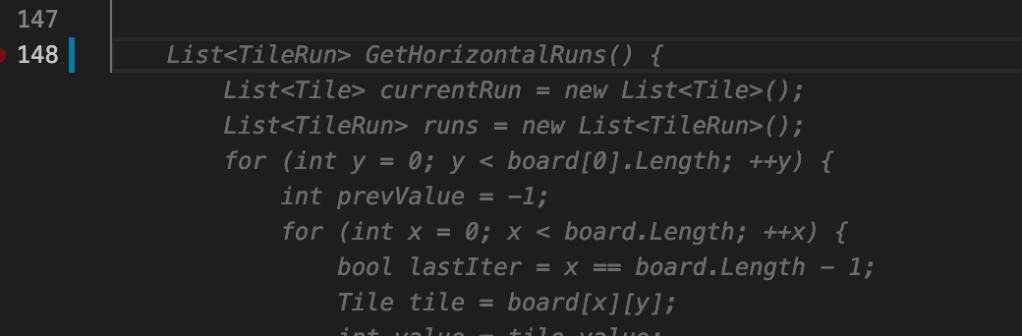
At the end of this function, I press enter and:
Note that bool lastIter went from y == board[x].Length - 1 to board.Length - 1. Fancy!
Its context-awareness is also great when you don’t want to have to look up math formulas:
(…it works for much more complicated math, too.)
And it saves tons of time writing out annoying debugging messages or ToString functions:
It also taught me C#’s $-formatting and rolls with other formats as you go, e.g., if you prefer (x,y) format.
The downside of using this is that I’m much more likely to repeat code, because I don’t have to write it all out. For example, in the GetVerticalRuns/GetHorizontalRuns functions above, I probably would have pulled out the loops into a common function if I had to write it myself. However, I also probably would have messed it up on the first try.
If you do any programming, I highly recommend signing up for Copilot. It takes away a lot of repetitive, annoying, and route work and lets you concentrate on actually getting your project working.
Unity has a simple, easy-to-use 2D text option under UI->Legacy->Text. However, this puts a text element on the weird ethereal Canvas that UI stuff sits on, which is probably not what you want (or at least not what I want). I want my text to be nested in other sprites in my scene. To do this, we can use TextMesh Pro objects.
TextMesh Pro was a Unity acquisition in 2017 and since then they’ve more-or-less integrated it into Unity. That said, the first thing you have to do is actually install it, so go to Window ->TextMeshPro -> Import TMP Essential Resources. Now you can use it.
To actually use TextMesh Pro, create a GameObject -> 3D Object -> Text (TextMeshPro). There is a similarly-named component under UI, but do not be fooled! If you use that one, it’ll be placed on a Canvas. Stick with the sprite-y 3D Object one, even in a 2D game. Now you can nest this object as a child of your other GameObjects and local scaling and positioning will work correctly.
From your scripts, you can reference TextMeshPro through its intuitively named package. Start with:
// Such package. Wow.
using TMPro;
Then the component is of type TMP_Text, so you can do:
// This class name...
TMP_Text scoreText = scoreObj.GetComponent<TMP_Text>();
scoreText.text = "Score: 0";
And that’s it. Now you have a nice text block that you can treat like a “normal” Sprite, not some weird 2D thing that lives on its own detached plane of existence.
(Side note: I’ve been mainly using Python for the last few years, so I’m very salty about how ambiguous and terribly-named packages in C# are.)
Let’s say there’s a nice house, around 100 years old, on a street. It’s been well-maintained and had normal renovations done over time to keep it comfortable and practical to live in (electrics upgrades, HVAC improvements, new roof when necessary, etc.). Now, suppose an inventor buys the empty lot next door. This inventor loves the old house so much he creates a machine to duplicate it in every detail down to the last molecule. Now there are two identical houses next to each other on the street.
The new one will immediately be deemed uninhabitable by the city.
The problem is that construction needs to adhere to building codes, which are the minimum standards to which a building must be built. These get stricter and stricter over time, so there is no chance that the 100-year-old house complies with them (likely offenders include insulating-ness of walls and windows, stair width, porch railings, and hundreds of other things). The weird thing is that the building code is supposed to be the minimum standard, but it obviously isn’t: literally most of the US lives in houses that wouldn’t be approved if they were new construction.
So building codes are too strict in one direction (new housing) and too lenient in another (old housing). There’s obviously a distinction between the true minimum (below which a building is uninhabitable) and the desired minimum (our current building code). Let’s call them BMBC (Bare Minimum Building Code) and DBC (Desired Building Code).
My modest proposal: allow people to build houses that only meet the BMBC. However, tax property for every standard in the DBC that the house fails to meet. Want that spiral staircase? No problem, but it’ll cost you $4k/year for the rest of your life.
Note that this does not exempt old houses. If you have a 23-bedroom house built by a robber baron at the turn of the century and the new DBC says all windows must be triple-glazed, you can either make sure all 6,000 windows are triple glazed or pay your new tax on being energy ineffecient.
This will have a stimulating effect on real estate. Housing prices, particularly for older houses, will be much more affordable to young people. This will create a virtuous cycle of young people with money and energy bringing old houses up to the DBC, and meanwhile older people can move into more modern housing. Modern housing will be more compatible with seniors’ mobility constraints and have lower carrying costs (since property taxes will be lower and more predictable). Plus, it’ll create ongoing employment in the construction industry and keep US housing in tip-top shape.
To sum up: housing is either safe or not. We should encourage more safe and efficient choices, but right now old houses are absurdly advantaged. If we want more and cheaper housing, the BMBC makes it easier to build new housing and the DBC incentivizes keeping old housing up-to-date.
Last night I was walking Domino and a woman passed us pulling a wagon of obviously-just-bought stuff from Home Depot. A guy behind her leaned down to adjust one of the items and I thought “Oh, I guess they’re together.” Then he picked it up, did a 180, and started walking away.
I realized what was happening and shouted “Hey!” and made a half-hearted attempt to grab the guy. He took off and the woman dropped the wagon handle and ran after him. I took up a post guarding the wagon, since apparently it needed guarding. A minute later she returned, her chase unsuccessful.
“It was just wheels,” she told me. “Not anything too important.”
“That’s good,” I replied.
Still, it’s the first time in years I’ve witnessed such blatant theft.
Here is the (roughly 52-step) process for testing your Unity game on an Android device.
In Unity Hub, go to Installs -> Settings -> Add Modules -> Android Build Support and make sure Android SDK & NDK Tools and OpenJDK are installed. If you need to install them, you’ll have to restart Unity afterwards to pick up on the change.
In Unity, go to File -> Build Settings and select Android. Make sure all of your scenes are included and select Build. This will pop up a naming dialog, which will have “.apk” added as an extension when built. In this example, I’m going to call it “game_dev”.
Once the build is finished, you should have a file, game_dev.apk, ready to be installed on your phone!
Now you need to explain to your computer how to get an APK onto your phone. Install adb and connect your phone for debugging: under Developer Options on your phone, enable Wireless debugging. Then select “Pair device with pairing code”:
adb pair $IP:$PORT
<put in the 6-digit code from phone>
You only have to do this once… until your phone’s IP address changes. On my home wifi, this seems to happen pretty regularly, but YMMV.
Above the options for getting a code, your phone will display “Wifi Address”. This port is different from the one you just typed in and you need to use this one to actually connect to the phone:
adb connect $IP:$PORT_FROM_PHONE
Now your phone will doodle-doop to let you know it’s connected. You have to run the connect command every time your computer loses connection to your phone (e.g., you turn off your machine).
Now we can move the APK from your computer to your phone wirelessly. If you’re just running a one-off test, you can select “Build and Run” in Unity and it’ll load the APK in some temporary way onto your phone. This is nice for quick turnaround, but if you want to keep your game around a while, you might want to actually install the APK. To do that, run:
adb devices
If you have more than one device, you’ll have to specify which one you want to deploy your APK to:
Suppose we have a dataframe with a couple of columns and we’d like to merge them into one column with some delimiter. For instance, let’s take a restaurant with orders to fill:
dinner dessert
patron
Alice Steak None
Bob Fish Cake
Carol None Pie
And we want to combine the columns into:
patron
Alice Steak
Bob Fish, Cake
Carol Pie
Note that this is made more difficult by the missing values: if everyone would just order dinner and dessert, it would be much simpler. However, users gonna user so there are a couple of ways of doing this in Pandas. If we weren’t picky about formatting, we could simply do:
This is probably the most straightforward way of getting the formatting we want. However, this is a long messy line and gets worse as we add more columns (what about drinks? Appetizers?). We can get more elegant using aggregation to ignore the missing values, instead of having to fill them in and then strip them out at the end. First, we stack up the two columns into one:
df.stack()
patron
Alice dinner Steak
Bob dinner Fish
dessert Cake
Carol dessert Pie
This creates a multiindex on name and part of meal. Now we can group by person and join on ‘,’ for any foods they list:
If you have a 2D game with a board and you want to center it on the screen, here’s the best way I came up with to do it.
Suppose you have a variable-size board (could longer or shorter in either dimension) on a variable-sized screen (could be a phone, tablet, web browser, console, etc.). Given you want to center the board on the screen, leaving a small margin on each edge, you need to scale and position it correctly.
First we’re just going to find the width and height of the screen. ViewportToWorldPoint gets the coordinates at the upper-right corner of the screen and the camera is centered at (0, 0), so we actually need to double the URH coordinates to get the full width and height.
Vector3 world = Camera.main.ViewportToWorldPoint(
new Vector3(1f, 1f, 0f));
world *= 2;
Then we need to scale the board to fit within this screen. Thus, if the board is longer than the screen is tall, we have to make it shorter. If the board is wider than the screen, we have to squeeze it thinner. In either case, we want to keep the board at the same aspect ratio after shrinking, so we choose the axis that requires the most compression and scale both axes by that. This code assumes that transform is your board GameObject‘s Transform and board is a Vector2 of board width & height (e.g., for chess it would be new Vector2(8, 8)).
Finally, we need to center the scaled-down board on the screen. Since (0, 0) is the center of the screen, we want to position the board at (-width/2, –height/2). However, this isn’t quite correct: if we put a 1-unit sprite at (0, 0), Unity centers the sprite at (0, 0) so its left edge is at -.5. Thus, if we position the sprite at –width/2, its right edge ends up at 0. To adjust for this we need to offset by 1/2 of tile’s width, i.e., the 1/2 of the scaling factor.
Over the holidays I’ve been playing with game development in Unity, so I’m going to post a couple of things I’ve discovered that I think are handy. First up: setting a random seed for your game. Not exactly a groundbreaking discovery, but I implemented this early on and it’s game-changing (har har).
I added a method to log what the game’s random seed is and make it easy to set. Now, when I run into a bug, I can immediately reproduce it in subsequent runs.
The code is a short function that I put in my GameManager.cs:
using UnityEngine;
// If you are using System, disambiguate.
using Random = UnityEngine.Random;
class GameManager : MonoBehaviour {
void Awake() {
// ...
}
private void SetSeed(int state=0) {
if (state == 0) {
state = System.DateTime.Now.Millisecond;
}
Debug.Log("Random seed: " + state);
Random.InitState(state);
}
}
Now in GameManager.Awake, I can simply call SetSeed() (or SetSeed(123) if I’m trying to reproduce a specific failure). If I want to come back and debug something later, I can make a note of the seed with the bug report.
System.DateTime.Now.Millisecond returns a number between 0-999, so if you want more possible scenarios you might want to use a different mechanism for generating random seed. However, I liked having a 3-digit seed, since they’re pretty easy to read & remember.
I recently signed up for yCombinator’s cofounder matching platform. After a week, I deactivated my profile with over 100 founders (or potential founders) having reached out to me. That seemed like a lot of responses, which might be because I had fairly flexible requirements: open to someone technical or non-technical, geography didn’t matter, and a half-dozen areas of interest. (I’m a natural lurker, so I didn’t reach out to anyone myself.)
It was a fascinating experience and there were some amazing founders out there. I thought it would be interesting to give a very general overview of what I saw, without identifying details. So I went through all 100+ emails and made a spreadsheet. Aside from how to spell “Philadelphia,” here are the things I learned:
New York will inspire you
I was delighted to see nearly 30% of founders based in NYC! (This may have been selection bias, since I’m in NYC. But still, makes me happy.) Bay Area followed with 16 founders, LA with 10, and Austin with 5. Over 20% of founders were international and almost 20% were in non-traditional US areas (e.g., flyover states, Dallas, Florida, etc). I love that they weren’t all concentrated in the Bay Area.
Heal the world
I’ve been thinking that there are two paths to making the world a better place. Option 1: become a politician and write legislation to make people do what you want them to do. Option 2: build a business and make it such a compelling choice for people that they will literally pay you to make the change you want to see happen.
I think a lot of entrepreneurs see their business as a way to do good in the world, so it was unsurprising that 10% of founders explicitly wanted to build a business to help fix global warming (or similar ESG focus).
Crypto
A little less than 10% of founders wanted to work on blockchain-/defi-/dao-/nft-related startups. They did not seem to be the most <positive attribute here> tools in the shed, but it was a small sample. This had the only neg of the bunch, plus this gem:
“Working on [crypto project], if done correctly can change securities market for good—but you have to be daring enough ’cause it might just get banned.”
Thank you anyway, I am not that daring.
Bio is hot
Results skewed heavier towards biotech/healthcare than I thought it would (especially since I didn’t express any interest in these area), with over a dozen founders reaching out.
Limitations of my analysis
When people said they had an idea but I couldn’t figure out what it was, I just marked them as not having an idea. My recording of this was not totally impartial, but I did my best. For example, if someone said they were interested in making a marketplace on the blockchain, I’d file that under “crypto.” However, when someone said they were interested in making a marketplace of ideas, I didn’t know what to do with that.
Some startups defied categorization, which was kind of interesting. I don’t want to give real examples because it would be way too identifying, but stuff like, “It’s a trading platform for futures on Venetian masks designed for pets.” Um… fintech?
Getting personal: profile analysis
I noticed two extremes in the data: some people would basically be like, “I don’t have an idea, here’s my ho-hum bio.” The other end was “I have already launched my product and I have 10 previous exits and ask me about the time I wrestled a shark.”
I felt like the ho hum founders needed to at least bring an idea to the table. If you’re not technical, have no relevant accomplishments and no passions, you better at least come with some creativity. You can even say, “I’m not set on this,” if you want, just bring something!
On the other hand, the shark wrestlers need to calm the fuck down. I think that they’re much more like the people I would want to be in the startup trenches with, but I also don’t want to sign up for listening to the same “thrilling” story every day for the next 10 years.
(There were plenty of people in the middle, which was “I’m interested in <things>, I’m looking for <other things>, I bring these skills & relevant accomplishments to the table, here are a couple interesting tidbits about me.”)
Conclusion
I highly recommend the cofounder search if you’re interested in starting a startup! A lot of really interesting and accomplished people on there.
Let me know if there are other breakdowns you’d be interested in! And watch out for shark-wrestlers.
A lot of projects require scraping websites. I usually write a scraper, run it, it fetches all of the data, and then fails in some final step before writing it anywhere. Then I curse a bit and try to fix my program without being sure what the responses actually looked like. Then I rerun my script, crossing my fingers that I don’t go over any rate limits.
This isn’t optimal, so I’ve finally come up with a better system for this. My requirements are:
Only download a page once.
…for a given time period (e.g., a day). If I rerun after that time period, download the page again.
Make everything human-readable. I want to be able to easily find the response for a given request and visually inspect it.
Basic rate limiting support.
Not reinvent the wheel.
So basically, if I request http://httpbin.org/anything?foo=bar I want it to save the response to a file like ./.db/cache/2021-07-31/httpbin.org_anything_foo_bar. Then I can cat the file and see the response (or delete it to “clear” the cache). However, URLs can be much longer than legal filenames (and the human-readable scheme above could cause collisions), so I’m going to compromise and store the response in file with an opaque hash for a name (e.g., ./.db/cache/2021-07-31/e23403ee51adae9260d7810e2f49f0f2098d8a25c3581440d25d20d02e00ccb9) and then have a CSV file in the directory that maps request URL -> hash. It’s not quite as user-friendly as being able to just visually examine the filename, but I can just do:
I’m using Python, so for not reinventing the wheel, I decided to use requests-cache. The requests-cache package actually has an option to write responses to the filesystem, but I wanted some custom behavior: 1) the cache_map.csv file as described above and 2) naming cache directories by date. Thus, I implemented a custom storage layer for requests-cache to use.
requests-cache represents storage as a dict: each URL is hashed and then requests-cache calls the getter or setter for that hash, depending on if it’s reading or writing. Thus, to implement custom storage, I just have to implement the dict interface to read/write to the filesystem, plus keep my cache_map.csv up-to-date:
class FilesystemStorage(requests_cache.backends.BaseStorage):
def __init__(self, **kwargs):
# I'm using APIs that return JSON, so it's easiest to
# use the built-in JSON serializer.
super().__init__(serializer='json', **kwargs)
# A cache a day keeps the bugs at bay.
today = datetime.datetime.today().strftime('%Y-%m-%d')
self._storage_dir = os.path.join('.db/cache', today)
if not os.path.isdir(self._storage_dir):
os.makedirs(self._storage_dir, exist_ok=True)
# The map of filename hashes -> URLs.
self._cache_map = os.path.join(self._storage_dir, 'cache_map.csv')
# Load any existing cache.
self._cache = self._LoadCacheMap()
def _LoadCacheMap(self) -> Dict[str, str]:
if not os.path.exists(self._cache_map):
return {}
# Using pandas is overkill, but are you even a data
# scientist if you don't?
return pd.read_csv(self._cache_map, index_col='filename')['url'].to_dict()
# Dict implementation.
def __getitem__(self, key: str) -> requests_cache.CachedResponse:
if key not in self._cache:
raise KeyError
k = os.path.join(self._storage_dir, key)
with open(k, mode='rb') as fh:
content = fh.read()
# I want to be able to get the URL from the response,
# so adding it here.
url = self._cache[key]
return requests_cache.CachedResponse(content, url=url)
def __setitem__(self, key: str, value: requests_cache.CachedResponse):
# Note that `key` is already hashed, so we use `value`'s
# URL attribute to get the human-readable URL.
k = os.path.join(self._storage_dir, key)
with open(k, mode='wt') as fh:
json.dump(value.json(), fh)
# Update cache map
self._cache[key] = value.url
# Write the cache back to the file system.
(
pd.Series(self._cache, name='url')
.rename_axis('filename')
.to_frame()
.to_csv(self._cache_map)
)
# I don't plan on using these, so didn't both implementing them.
def __delitem__(self, key):
pass
def __iter__(self):
pass
def __len__(self) -> int:
return len(self._cache)
Now I add a simple cache class to use this custom storage:
class FilesystemCache(requests_cache.backends.BaseCache):
"""Stores a map of URL to filename."""
def __init__(self, **kwargs):
super().__init__(**kwargs)
storage = FilesystemStorage(**kwargs)
self.redirects = storage
self.responses = storage
Note that I’m using the same instance of my cache for both responses and redirects. This isn’t optimal if I were actually expecting redirects, but I’m not and my storage layer is designed to be a singleton (as implemented, multiple instances would clobber each other).
Now I create a request class that uses my custom cache.
import requests_cache
from typing import Any, Dict
from lib import custom_cache
class Requester(object):
def __init__(self):
self._client = requests_cache.CachedSession(
backend=custom_cache.FilesystemCache())
def DoRequest(self, url: str) -> Dict[str, Any]:
resp = self._client.get(url, headers=_GetHeader())
body = resp.json()
# The API I'm using always has a 'data' field in valid
# responses, YMMV.
if 'data' not in body:
raise ValueError('Unexpected response: %s' % resp.text)
return body
Finally, I want to support rate limiting. I used the ratelimit package for this. ratelimit is based on the Twitter API, which rate limits on 15-minute intervals. So if I was hitting an endpoint that allowed 10 requests/minute (10*15 = 150 requests per 15 minutes) then I could write:
This will block the program’s main thread if this function is called more frequently than the allowed rate limit (which may not be what you want, check the ratelimit docs for other options).
The downside of this implementation is that it still rate limits, even if you’re hitting the cache. You could get around this by checking the cache contents in Requester and then only conditionally calling DoApiCall, but this is left as an exercise for the reader 😉